I am working on two parts: one is the dynamic voltage scaling for
network processor, the other is the multi-core design to explore
trade-off between ILP and TLP, working with Changbo and Luke.
For the dynamic voltage scaling part, I have been hacking the
open-source Intel IXP simulation named Nepsim. This simulator
include power model for dynamic power estimation, and a leakage
model estimating leakage power as a fix precentage of dynamic
power. Currently I have started modifying the code and implement
the dynamic voltage scaling. First I will add in the Vdd-frequency
relationship for this simulator; then I will provide seperate
voltage supply for each processing cores; after that I implement
different packet arrival rates according to user-spcified input;
and finally I will put in the dynamic voltage scaling management
considering the transition overhead of each voltage regulator
module.
Figure 1 shows the performance and power when the network
processor is assigned different voltage and frequency.
This is static voltage assignment, not dynamic scaling.
The same voltage and frequency are assigned to all cores.
It is easy to see that there is no obvious optimal point
for both power and performance. Dynamic voltage scaling
can better explore the irregular behavior of packet processing.
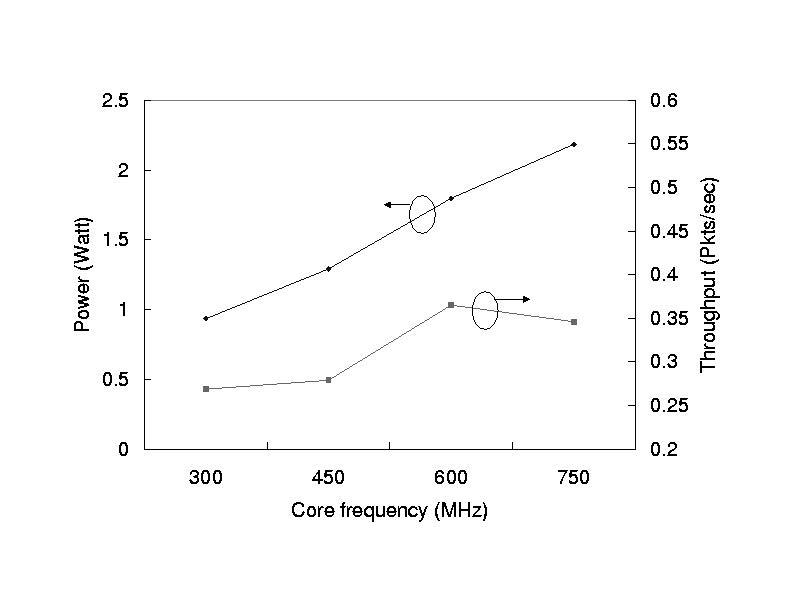
Figure 1: Performance and power with different core
frequency. Vdd is from 1.0V to 1.3V. SRAM frequency is 200MHz.
SDRAM frquency is 150MHz. IXbus (bus between on-chip FIFO
and MAC) frequency is 80MHz.
For the multi-core design part, below is the outline:
1. Target architecture: chip multi-processing (CMP). We don't
consider SMT this time but definitely need to consider it for
future development.
2. Benchmark characteristics: our optimization focuses on given
sets of benchmarks. For any benchmark, we characterize two
properties by profiling: (1) instruction level parallelism: this
property indicate the amount of ILP in this benchmark. This feature
can be presented by the IPC under ideal-case simulation (wide
issue-width superscalar, ideal branch prediction, unlimited number
of functional units, ideal caches). (2) memorism. This property
indicates the main memory dependency of this benchmark, i.e. rate
of memory request of this benchmark. This feature can be presented
by L2 cache miss rate for per unit L2 cache, for example, miss
rate / KB. Here we can simulate a few L2 cache settings and use
curve fitting to obtain the miss rate / KB.
3. Problem formulation: for given benchmark set with ILP and memorism
characteristics, we try to design a CMP to maximum performance under
the area. Power constraint can be considered later.
4. Cores: we can have two kinds of core designs: (A) homogeneous cores.
In this case, we only have to decide the number of core and the
configuration of each core (with clock frequency). (B) heterogeneous
cores. In this case the configuration of cores are different. The
homogeneous design is simple but the heterogeneous design can better
match the characteristics of each individual benchmark for better performance.
5. Performance metric is throughput. No only the IPC, but also the
clock frequency should be taken into account. For benchmarks with
high ILP, we tend to design large pipeline structure with wide
issue-width and multiple functional units. For benchmarks with
high memorism, we tend to design cores with large caches and also
reduce the number of cores.
6. Exploration: we use SA to obtain the optimal solution. Each SA
solution is evaluated quickly by leveraging the analytical superscalar
model and bus model. ILP and memorism of each benchmark should be fed
into the SA. This will take some thinking and discussions.
7. Comparison: we can have three comparison. First, we can compare
the performance of our CMP to a wide issue-width superscalar which
only explore ILP. Second, we can compare to the CMP which simply
put existing cores together. Third, we can compare to the ideal case.
8. Todo: first we need to profile the benchmarks. I can work on that.
Second we need a table of all microarchitecture components. For example,
we may have different caches and different branch predictors to choose.
For each component with different configuration, we need to obtain the
area and access latency in ns. Changbo has similar data in previous
submission and can build up the table by making some changes on previous
data. We can target at 65nm technology. Third, the design of interconnect
pipeline really depends on the clock frequency, which is something
considered during our optimization. So the interconnect pipeline
should be decide on-the-fly. Fourth, we should formulize the SA
procedure. I will work with Changbo and Luke for this.